-
소프트웨어 크기 결정 및 경계에 대한 고찰Thinking 2023. 8. 14. 22:28
문제 제기
우리는 매년 새로운 시스템을 구축하고, 동시에 수많은 레거시 시스템을 운영할 책임을 갖는다.
시스템의 개수는 매년 지속적으로 늘어나고, 시스템의 통합과 분리 작업이 반복적으로 진행되는 경향이 있는데, 시간이 갈수록 여러 시스템들이 중복 기능을 포함하는 경우가 많아지고, 각 시스템들은 메시지 또는 데이터를 기반으로 강하게 결합되면서 하나의 변경 작업이 알수 없는 곳까지 영향을 끼쳐, 유지보수가 상당히 어려워지기도 한다.
오래된 조직일수록 이런 문제에 직면할 가능성이 높아 시스템 구조(+조직 구조)에 대한 고민을 많이 하게된다.
즉, 어떻게 시스템을 설계하고 운영하는 것이 비용적으로 가장 효율적인지 결정해야하는데, 중복 개발은 피하면서 시스템 간의 의존성은 줄여 개발 및 유지보수를 쉽게 하고, 상호 운영과 테스트, 배포 작업을 적은 인력으로 쉽고 빠르게 할 수 있는 체계를 적용해야 한다.
본 칼럼에서는 애플리케이션 크기 결정과 경계 분할에 따른 영향도를 설명하고, 대규모 시스템 생태계를 구축하는 경우 모듈러리티(Modularity)를 높일 수 있는 구조를 설명하고자한다.서비스 추상 수준의 결정
서비스 추상화 수준 높이기
과거에는 주로 필요한 서비스가 하나의 애플리케이션에 모두 들어가있는 모노리식(Monolithic) 아키텍처를 선호하였다. 이 방식은 시스템에서 제공해야 하는 모든 요구 기능이 하나의 배포 가능한 모듈로 패키징되어 개발/배포되는 방식이다.

그림 출처: https://bcho.tistory.com/948 특정 도메인에서 필요한 모든 기능을 하나의 웹 시스템에서 통합 제공됨으로써 개발자는 하나의 애플리케이션만 개발하면 되고, 관리자는 전체 시스템이 동일한 프로세스와 기술을 가지고 개발되기 때문에 조직 관리에도 용이한 장점을 가진다.
하지만, 이 방식은 하나의 시스템이 너무 많은 책임(Responsibility)을 갖고 있어, 라인 횡전개나 신규 기능 대응 등으로 새로온 책임이 계속해서 Add-on 되면서 시간이 흐를수록 거대해진다. 애플리케이션이 거대해질수록, 하루에도 수차례 진행되는 빌드와 배포 비용이 높아지고, 내부 코드들은 강하게 결합되어 서비스 및 데이터 전체를 알고 있는 개발자 아니면 이를 이해하고 변경하기 어려워진다 (심지어 역사마저 알고 있어야 한다). 전체 구조와 뒤엉킨 의존방향을 이해하기 어렵기 때문에 개발자들은 중복코드를 만들어 안심할 수 있는 방법을 주로 채택하기도 한다 (이러면서 더욱 거대해진다). 또한 일부 서비스의 성능 문제가 전체 서비스에 영향을 끼치기도 하며, 일부 기능의 변경이 전체 시스템의 품질에 영향을 준다.결국 운영 비용은 매년 급격하게 증가하고, 서비스 신뢰성은 내려가며, 고객의 요구사항을 빠르게 제품화할 수 없게 되면서 서비스 만족도는 떨어지게된다.
서비스 추상화 수준 낮추기
2010년도 중후반부터 MSA 개념이 널리 퍼지고 정착되는 것을 보면서, 서비스를 작게 쪼개는 것에 대해 고민하게 되었다. 이 개념은 2014년도에 마틴 파울러에 의해 정의되었는데, 그 사상은 SOA나 분산 아키텍처 등으로 오래전부터 존재하였고, 이를 보다 경량화하여 구체적으로 정리한 것뿐이다. 단지, 이 시기에 분산 서비스들을 효율적으로 관리할 수 있는 쿠버네티스와 DevOps 체계가 함께 정착하며, MSA를 포함한 3종 세트가 IT업계에 잘 뿌리내린 것이라 생각된다.

그림 출처: https://fastcampus.co.kr/dev_online_istio MSA 구성 요소
MSA는 시스템을 작은 서비스단위로 분리하고 API Gateway를 통해 표준 인터페이스(Rest API)를 제공하며, 서비스 레벨에서 데이터를 캡슐화하여 복잡한 데이터 의존성을 제거한다. 공통 관심사(인증/인가)는 API Gateway에서 함께 다뤄질 수 있으며, Client(UX) 입장에서는 API Gateway를 통해 여러 개의 서비스들을 마치 하나의 시스템인 것처럼 다룰 수 있다.
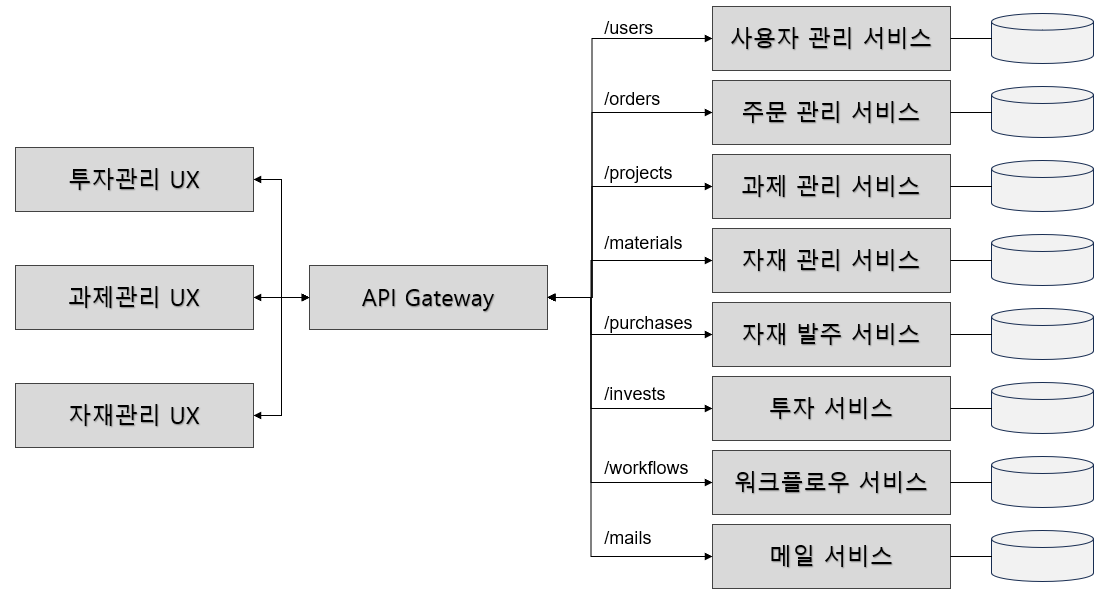
MSA 장점
각 서비스는 독립적으로 개발/배포될 수 있다는 장점을 가지며, 서비스 간 의존성은 최소화되어 변경 비용이 낮아진다. 물론 서비스의 응집도를 높게 설계해야 하고 의존 방향에 대한 Layer 정책이 필요하다.
서비스 Level에서 Business Logic과 Data가 캡슐화되어, 이를 접근할 수 있는 온전한 책임을 해당 서비스만 갖게된다. 외부에서 해당 Data에 접근하기 위해서는 해당 서비스가 제공하는 API를 통해서만 가능해야한다. 외부 시스템에서 서비스 내부를 모르기 때문에, 비지니스나 데이터가 보다 안전하게 격리되며, 변경이 발생하여도 외부에 직접적인 영향을 주지 않는다.
만약, 여러 애플리케이션이 동일한 Data를 접근하여 다룰 수 있다면, 중복 기능이 여러 시스템에서 개발되거나, 특정 시스템에서 비지니스가 의도대로 동작되지 않기도 한다. 또한 Data의 변경에 대한 영향을 평가하기 어려워진다.
만약 조직에서 운영조직으로 부터 관리되는 높은 가용성의 DBMS를 활용할 수 있다면, 서비스 별 계정을 분리하고 타 계정으로 Grant를 부여하지 않는 방식으로 Data를 격리시키는 것이 효율적인 방법이라 생각한다.
또한 확장성에서도 장점을 갖는데, 하나의 서비스에 과부하가 걸리더라도 다른 서비스에 영향을 주지 않으며, 서비스 스케일링을 통해 문제를 쉽게 해결할 수 있다.
결론적으로 MSA의 장점은 높은 유지보수성이다. 성능이나 자원 효율성은 나빠진다. 그럼에도 불구하고 우리는 운영 비용과 직결되는 유지보수성 하나 때문에 서비스를 작게 나누는 모델을 고민해 봐야 하는 것이다. 변경과 배포를 쉽게하여 운영 비용을 낮추고, 고객의 요구사항을 빠르게 반영해주어 제품 경쟁력을 갖추는 것이 더욱 중요한 가치라고 생각하는 것이다.
MSA 단점
반면, 서비스를 작게 분리하면 발생하는 가장 큰 문제는 수 많은 서비스들의 운영 문제이다. 하지만 2015년에 Kubernetes가 등장하여 서비스 운영에 대한 상당 부분을 책임지며, 분산 아키텍처의 단점을 해결해주었다.
참고로 쿠버네티스는 다음과 같이 운영 업무를 자동화 해준다.
더보기- 서비스 복제 구성 및 트래픽 분산 처리 자동화
- 특정 서비스 과부하 시, 자동 서비스 개수 증설
- 서비스 이상 감지 시, 신규 버전 자동 패치 및 리스타트
- 서버 이상 시, 다른 서버로 자동 이전 (대규모 파드 이전이 발생하면 상당히 느리다.)
- 다양한 배포 전략 제공 (수차례 배포하여도 사용자가 알지 못한다.)
- 사용자 인증, 인가 등 공통 관심사 지원
- 다양한 데브옵스 생태계나 활용도 높은 오픈소스가 Kubernetes를 기반으로 제공되며, 설치가 쉽고 이식성이 뛰어남
이는 일부에 불과하며 다양한 오픈소스를 활용하여, 네트워크를 통제하며 전체 생태계를 만들고 관리할 수 있다.
트렌젝션 일원화 문제도 MSA의 주요 단점으로 지적된다. API 기반의 여러 서비스를 하나의 트렌젝션으로 묶는 것은 불가능하다. 멱등성을 보장하지 않는 기능은 보상 트렌젝션 로직을 함께 구현해주어야 한다. 만약 하나의 Use Case에 분산 트렌젝션이 많다면, 관련 서비스들간의 결합도가 높다라고 말할 수 있다. 이는 서비스의 추상 레벨을 올려 통합 구축하는 것을 검토해 볼 수 있다. (물론 기능간의 결합도는 설계 단계에서 파악되어야 한다. 운영 단계에서 리펙토링은 현실적으로 어렵다.)
통합 테스트의 어려움도 존재한다. 하나의 기능이 여러 서비스를 거쳐 수행됨으로써 테스트의 난이도가 상승한다. 오류 트레이스 및 재현에 있어서도 난이도가 올라간다.서비스 추상 레벨 결정하기
최근 시스템을 무턱대고 MSA로 구축하거나 진화형 모델로 일부 서비스만 MSA로 전환하는 사례를 많이 봤을 것인데, 많은 조직들이 대부분 실패를 경험해 봤을것이라 생각한다.
우선 MSA는 상당히 높은 수준의 팀의 성숙도를 요구한다. 즉, 팀원들의 대부분이 DevOps에 어느정도 익숙한 엔지니어야하며, 배포 및 운영의 상당 부분이 자동화되어 있어야 한다. (여기서 DevOps는 CI/CD만을 일컫는 것이 아니라 클라우드 환경에서 오픈소스를 다루며 개발, 운영 생태계를 구성할 수 있는 엔지니어를 말한다.)
Kubernetes를 잘 다루는 DevOps 엔지니어는 글로벌하게 수요가 높아, 일반적인 SI 기업에서는 구하기 어렵거나 비용이 매우 높다. 특히 우리 회사는 Offline On-premise 환경에 구축해야 하기 때문에 더욱더 난이도가 상승하고 비용이 올라간다.
따라서 서비스를 작게 나누기 전에 조직 구조, 역량, 환경까지 사전에 고려해야 할 제약들이 많다. 아키텍처를 결정할 때는 항상 제약사항이 존재하는데, 비지니스 규모, 가용 시간, 가용 비용, 팀의 기술 성숙도 그리고 조직 거버넌스(기술 표준) 등이 대표적이다.
자사에서 진행되는 대부분의 개발 프로젝트들은 서비스 복잡도가 낮고, 가용 시간과 비용이 매우 작기 때문에, 아키텍처 무관 설계(조직에서 전통적으로 내려온 검증된 기술, 방법론)를 기반으로 프로젝트를 진행하는 경우가 많다. 이 방법은 프로젝트를 가장 빠르게 구현하면서 리스크를 적게 가져가는 방법이기도 하다. 기능과 아키텍처는 직교 관계이기 때문에, 어떤 아키텍처를 사용하더라도 기능은 동작하도록 구현할 수 있다. 하지만 현재 도메인 환경에서 가장 적합한 아키텍처를 채택하고 적절한 전략들을 구현한다면, 기능이 "잘", "안정적으로", "빠르게" 동작하고 요구 기능을 "쉽게 변경"이 가능하도록 구축할 수있다. 아키텍처의 역할은 그뿐이다. 아키텍트는 상위 레벨부터 하위 레벨까지 각 노드, 컴포넌트, 모듈의 크기와 경계, 의존방향을 결정하고 이를 구현될 수 있게 쪼개(Decomposition) 나가면 된다.MSA 전환 사례
다음은 필자가 관찰했던 모놀로식 아키텍처에서 MSA로 넘어간 몇가지 사례를 소개한다.
도커는 가장 널리 사용되는 컨테이너 런타임이다. 실제 컨테이너 기반의 서비스를 세상에 정착시키는데 가장 큰 공을 세운 제품 이지만, 국제 컨테이너 표준기구인 CNCF에서는 위 제품을 표준 기술로 채택하지 않았다. 그 이유는 도커는 이미지 관리, 이미지 빌드, 이미지 실행 등 하나의 데몬이 너무 많은 책임을 갖고 있었는데, 특정 기능에서의 장애가 도커 데몬 전체의 장애나 성능 저하로 전파될 수 있었고, 쿠버네티스에서 사용하는 경우, 해당 노드 전체 장애로 전파될 수 있기 때문이었다. CNCF에서는 Cri-O 제품을 표준 기술로 채택하고, 각각의 세부 기능들을 Podman, Buildah, Skopeo 컴포넌트로 분리하여 구동될 수 있게 하였다. 또한 Docker Image를 호환하며, daemon-less, root-less한 구동방식으로 Docker가 가진 불안정한 부분을 제거하였다.
작년에 CVAT이라는 라벨러 오픈소스를 도입하였는데, 하나의 서비스에서 프로젝트 생성, 이미지 업로드, 오토라벨링 등 다양한 기능을 제공한다. 하지만 이미지를 대량으로 업로드 하는 과정에서 자원이 많이 소모되면서, 다른 기능까지 성능 저하 문제가 발생하였다. 최근에 릴리즈된 CVAT을 설치해보면, 각각의 기능 단위로 서비스가 분리되어 배포되는 것을 볼 수 있다. 즉 이미지 업로드 기능에 부하가 크더라도, 라벨러 작업을 하는 기능에 영향을 끼치지 않게 되었으며, 이미지 업로드 서비스만 레플리카셋을 구성하여, 다중 사용자의 요청을 동시에 안정적으로 처리할 수 있게 되었다.
이제 (글이 너무 길어지는 것 같아..) 필자가 생각하는 사내에서 대규모 서비스 구축 시, 이상적이라 생각하는 아키텍처를 제안하고, 특징을 설명하도록 하고자 한다.
대규모 서비스 아키텍처 예시
대규모 서비스가 요구되고, 향후 지속적인 서비스 확장이 고려되는 경우, 다음과 같은 서비스 아키텍처를 제안하고 구축할 수 있다. Software 개발자가 파란색으로 표시된 Service Group 영역을 책임 지며, 나머지 회색 영역은 DevOps 엔지니어가 생태계를 책임진다. 따라서 분산 아키텍처 운용에 필요한 환경 구축 및 필요한 오픈소스 서비스 Integration 작업을 DevOps 엔지니어가 진행하게된다.
그럼 하나씩 분해해서 살펴보도록 하겠다.
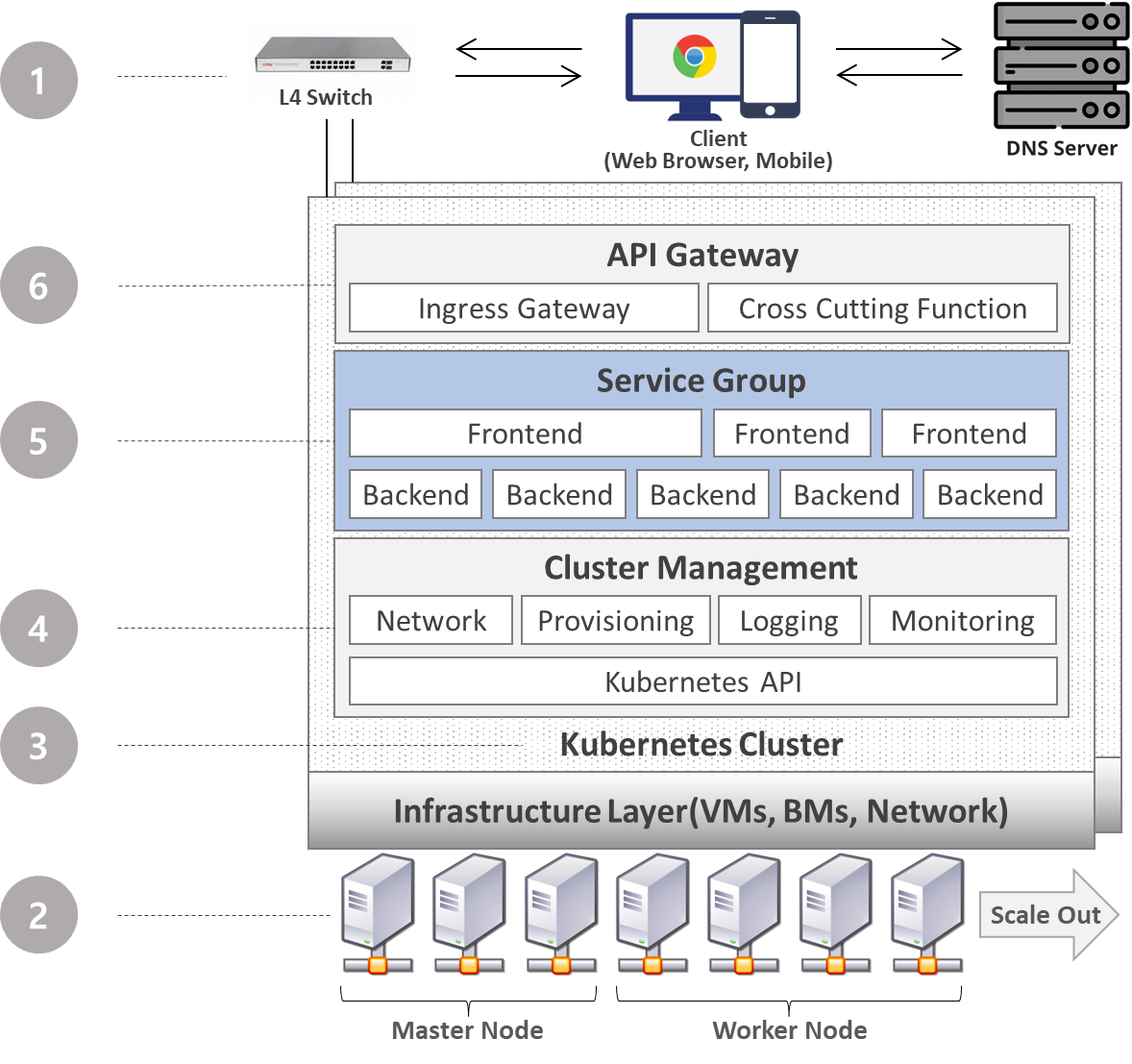
- Client는 DNS Server로 부터 Domain 주소에 해당하는 IP 주소를 할당받는다. 사용자는 https://ai-portal.asan.samsungdisplay.net과 같이 식별이 용이한 도메인 주소를 브라우저에 입력하면, https://xx.xx.xx.xxx:8080과 같은 IP 주소를 받는다. L4 Switch를 통해 이중화 되어있는 클러스터에 로드 밸런싱하여 고가용성의 서비스를 제공할 수 있다.
- 하나의 클러스터에는 마스터 서버를 최소 3대 이상으로 구성하며 리더 선출 알고리즘을 위해 홀수개로 구성해야한다. 마스터를 복수개 서버로 HA구성 하였다고 하더라도, 클러스터 전체의 장애 위험이 존재한다. 클러스터 레벨에서 분리 구축하고 DNS나 L4 Switch로 분산 처리될 수 있도록 해야할 것 같다.
워커노드의 개수는 제약이 없으며, BM이든 VM이든 리눅스 머신이면 조인이 가능하다. 가용 자원에 따라 스케일 인/아웃이 용이하며, VM인 경우 수직 스케일링도 용이하다. - N개의 Node를 하나의 Cluster로 구성하여, 마치 하나의 서버처럼 다룰 수 있게 한다. 마치 OS 프레임워크처럼 수많은 서비스 운영에 필요한 기능들을 제공해준다.
- Kubernetes는 API를 제공하여, 상위 계층에서 클러스터의 오브젝트나 자원을 조작할 수 있다. 즉 원하는 시점에 특정 서비스를 띄우고 자원을 할당, 회수하는 등 클라우드 네이티브한 서비스를 쉽게 구현할 수 있다. 다양한 오픈소스들이 이 API를 통해 DevOps 생태계를 제어하고 모니터링 할 수 있으며, 주요 프로그래밍 언어 또한 API를 쉽게 연동하기 위한 Library가 제공되어 필요한 기능을 편하게 구현할 수 있다. 네트워크 제어, 자원 프로비저닝, 서비스 로깅, 자원 모니터링 등 서비스 생태계 구성에 필요한 모든 영역에 다양한 오픈소스들이 존재하며, 이를 설치하고 Integration하여 환경을 구성할 수 있다.
- 실제 애플리케이션 개발자가 관심을 가지는 서비스 그룹 영역이다. 기본적으로 프론트앤드와 백앤드를 분리하는 것이 성능의 단점은 있지만, 유지보수성과 가용성이 좋고 서비스 모듈화를 통해 중복 개발을 방지할 수 있는 장점이 있다. 백앤드에서는 책임지는 기능을 API로 노출하고, 프론트앤드는 제공되는 API들을 조립하여 새로운 UX를 구성할 수 있다. 물론 이는 이상적인 얘기일 수 있다. 모든 Use Case에서 범용적으로 쓸 수 있는 API는 존재하기 어렵다. 해당 API를 사용하는 Use Case별로 Actor나 기능이 다르기 때문에, 새로운 Use Case가 발생하면, 해당 API의 버전을 올릴지 아니면 새로운 API를 제공해줄지, 백앤드 담당자가 결정해줘야겠다.
필자의 환경에도 굉장히 많은 서비스 API들이 제공되고 있고, 이러한 서비스들을 어떻게 조립하여 새로운 서비스를 만들지 고민한다. 또한 프론트앤드와 백앤드를 분리하는게 프로젝트를 병렬로 진행하기 좋으며, 상호 패키지 의존성이 제거되며, 크기가 작아지고 배포 및 통합 테스트가 용이하다. - API Gateway는 내부 서비스에 접근하고 제어하는 역할을 책임진다. 서비스로 접근하는 모든 요청은 API Gateway를 통한다. 내부 서비스간의 상호작용 역시 API Gateway를 통해 처리된다. 외부로 노출되는 서비스 주소도 역시나 API Gateway 주소가 된다. Access Point가 단일화 되기 때문에 서비스 개수가 많아져도 외부로 노출시켜야 하는 IP:Port가 전혀 없다. Request URI 에 따라 규칙에 해당하는 서비스로 라우팅 해준다. 또한 인증, 인가, 로깅과 같은 서비스 횡적 관심사를 해당 레이어에서 제공해 줄 수 있다. 이를 통해 모든 서비스를 내부를 숨기고 진입점에서 모든 요청을 통제할 수 있게 된다. 보안 정책 변경이 용이하며, 애플리케이션 개발자는 비지니스 구현에만 집중할 수 있게 한다.
마치며...
다시 얘기하지만, 위에 제시한 아키텍처나 필자의 의견이 정답이 아니다. 소프트웨어 아키텍처는 좋고 나쁨이 없으며, 상황과 제약에 따라 최선의 안이 결정되며, 하나가 좋아지면 하나가 나빠지는 Trade-Off 특성에 따라 의견이 다를 수 있다. 중요한 것은 새로운 프로젝트를 진행할 때, SW 방법론이든 아키텍처든 프로그램밍 언어든 새롭게 배운것을 일부 적용해보고 경험해 보는 것이다. 직접 경험을 해봐야 해당 이론이 가진 실질적인 장/단점이 머리속에서 정리되고, 저자가 말했던 그 의미가 제대로 해석되기도 한다. 매년 새로운 시스템을 만들 때마다 마음에 드는 적이 단 한번도 없지만, 그래도 내년에는 올해보다 나은 시스템을 만들 수 있을 것 같다는 생각이 든다면, 그만큼 기술적으로 성장한 것이라 생각한다.